
Kubernetes é o novo servidor de aplicações
This post was originally posted on Red Hat Developers and this version is a translation to Portuguease.
Você já se perguntou o por quê estamos fazendo o deploy de aplicações multi-plataforma usando contêineres? É somente uma questão de seguir alguma “modinha”? Neste artigo, eu vou fazer algumas perguntas provocativas para justificar o porque Kubernetes é o novo servidor de aplicações.
Você pode ter notado que a maioria das linguagens são interpretadas e usam “runtimes” para executar o código fonte. Em teoria, a maioria dos códigos Node.js, Python, e Ruby podem ser facilmente portados de uma plataforma (Windows, Mac, Linux) para outra plataforma. Aplicações Java vão ainda mais longe por possuírem sua classe Java transformadas em um bytecode capaz de ser executado em qualquer lugar que tenha uma JVM (Java Virtual Machine).
O ecossistema Java fornece um formato padrão para distribuir todas as classes Java que são parte da mesma aplicação. Você pode empacotar estas classes como um JAR (Java Archive), WAR (Web Archive), e EAR (Enterprise Archive) que contém o frontend, backend, e todas as demais bibliotecas embutidas. Então eu lhe pergunto: Por quê você utiliza contêineres para distribuir sua aplicação Java já que supostamente este deveria ser facilmente portável entre os ambientes?
Responder esta pergunta à partir da perspectiva de um desenvolvedor nem sempre é óbvio. Mas pense por um segundo sobre seu ambiente de desenvolvimento e algumas dos possíveis problemas causados pela diferença com o ambiente de produção:
- Você usa Mac, Windows, ou Linux? Você já enfrentou problemas relacionados a
\versus/como separador arquivos? - Qual versão da JDK você usa? Você usa Java 10 no ambiente de desenvolvimento, mas a produção usa a JRE 8? Você já enfrentou algum bug introduzido pelas diferenças da JVM?
- Qual versão do servidor de aplicações você usa? O ambiente de produção usa a mesma configuração, patches de segurança, e versão da biblioteca?
- Durante o deploy em produção, você já encontrou algum problema com o driver JDBC que você não encontrou no ambiente de desenvolvimento devido a versões diferentes do driver ou do banco de dados?
- Você já teve que solicitar ao admin do servidor de aplicações para criar um
datasourceou uma fila JMS e esta foi criada faltando uma letra?
Todos os problemas acima são causados por fatores externos a sua aplicação, e uma das grandes vantagens sobre contêineres é que você pode fazer o deploy de tudo (por exemplo, uma distribuição Linux, a JVM, o servidor de aplicações, bibliotecas, arquivos de configuração, e finalmente, sua aplicação) dentro de um contêiner previamente construído. Além do mais, executar um simples contêiner que tem tudo embutido é incrivelmente mais fácil do que levar seu código para a produção e tentar resolver os problemas quando alguma coisa falhar. Uma vez que é fácil executar, também é fácil escalar a mesma imagem do contêiner para múltiplas réplicas.
Empoderando a sua aplicação
Antes de contêineres se tornarem bastante popular, vários RNF (Requisitos não funcionais) como segurança, isolamento, tolerância a falhas, gerenciamento de configuração, e outros, eram fornecidos pelos servidores de aplicação. Em uma analogia, os servidores de aplicação foram planejados para serem para a aplicação o quê os “CD Players” são para os CDs.
Como desenvolvedor, você seria responsável em seguir um padrão pré-definido e distribuir sua aplicação em um formato específico, enquanto, do outro lado, o servidor de aplicações executaria sua aplicação, dando-a funcionalidades adicionais que variam de acordo com o servidor. Nota: No mundo Java, o padrão para estas funcionalidades fornecidas por um servidor de aplicações foi recentemente movida para a Fundação Eclipse. O trabalho do Eclipse Enterprise for Java (EE4J), resultou no Jakarta EE. (Para mais informações, leia o artigo Jakarta EE is officially out ou veja o vídeo do DevNation live: Jakarta EE: The Future of Java EE )
Seguindo a mesma analogia do “CD Player”, com a ascensão dos contêineres, a imagem do contêiner se tornou o novo formato do “CD”. De fato, a imagem do contêiner não é nada mais que um formato para distribuir seus contêineres. (Se você precisar de um melhor entendimento do que sejam imagens dos contêineres e como elas são distribuídas, veja A Practical Introduction to Container Terminology)
Os reais benefícios da utilização de contêineres acontece quando você precisa adicionar funcionalidades “enterprise” na sua aplicação. E a melhor maneira de fornecer estas funcionalidades para uma aplicação “contêinerizada” é através da utilização do Kubernetes como uma plataforma para tais aplicações. Adicionalmente, o Kubernetes fornece uma excelente fundação para outros projetos como o Red Hat OpenShift, Istio, e o Apache OpenWhisk de forma a produzir aplicações robustas e de qualidade.
Vamos explorar nove destas funcionalidades:
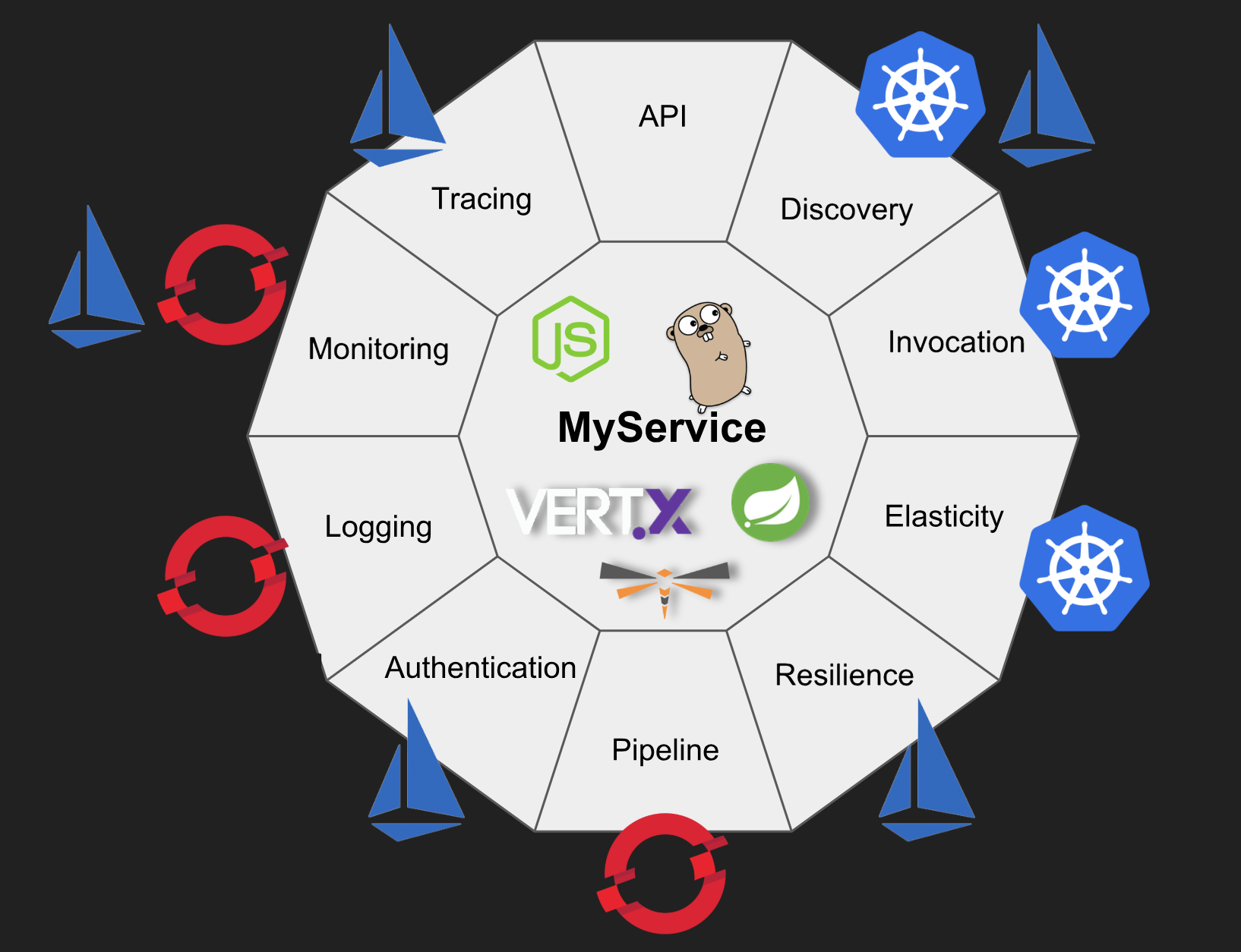
1 – Service Discovery
Service discovery é o processo de descobrir como se conectar a um serviço. Para obter muito dos benefícios de aplicações cloud-native e contêineres, você precisa remover a configuração de dentro das imagens do contêiner de maneira que você possa usar a mesma imagem em todos os ambientes. Externalizar a configuração da sua aplicação é um dos princípios chave de uma aplicação 12-factor.
O Service discovery é uma das formas de obter a informação de configuração o ambiente ao invés de estar “hardcoded” na aplicação. O Kubernetes fornece um mecanismo de Service Discovery embutido. O Kubernetes também fornece ConfigMaps e Secrets que removem a configuração de dentro da aplicação “contêinerizada”. Secrets resolve alguns dos desafios de se armazenar credenciais para se conectar a serviços como um banco de dados.
Com o Kubernetes, não existe a necessidade de usar um servidor externo ou um framework. Apesar você poder gerenciar as configurações do ambiente usando os arquivos YAML do Kubernetes, o OpenShift fornece uma GUI em um CLI que facilitam o gerenciamento para times DevOps.
2 - Basic invocation
Aplicações executando dentro de contêineres podem ser acessados através do Ingress - em outras palavras, rotas do “mundo externo” ao serviço que você está expondo. O OpenShift fornece o objeto route usando HAProxy, que possui diversas funcionalidades e estratégias de load-balancing. Você pode usar as funcionalidades de roteamento para fazer rolling deployments. Isto pode ser usado para o básico de estratégias mais sofisticadas de CI/CD. Veja “6 – Build and Deployment Pipelines” abaixo.
E se você precisar executar um job como um processo batch, ou simplesmente utilizar todo o cluster para computar um resultado (como calcular o Pi, por exemplo)? O Kubernetes fornece objetos job para este caso de uso. Também existe cron jobs para estes jobs que são baseados em agendamento.
3 – Elasticity
Elasticidade no Kubernetes é resolvido através da utilização de ReplicaSets (que eram antigamente chamados de Replication Controllers). Assim como a maioria das configurações no Kubernetes, o ReplicaSet é uma maneira de reconciliar um estado desejado: Você diz ao Kubernetes qual o estado desejado que o sistema deve possuir e o Kubernetes descobre como tornar este estado uma realidade. Um ReplicaSet controla o número de réplicas ou o número de cópias que uma aplicação deve possuir a todo momento.
Mas o que acontece quando você constrói um serviço que é mais popular do que você planejou e você precisa de mais poder computacional? Você pode usar o Horizontal Pod Autoscaler do Kubernetes que escala o número de pods baseado na utilização da CPU (ou, com métricas customizadas, ou com qualquer outra métrica fornecida pela aplicação).
4 – Logging
Uma vez que seu cluster Kubernetes pode e irá executar diversas réplicas da sua aplicação contêinerizada, é importante que você agregue estes logs de forma que eles sejam visualizadas em um único lugar. Também, de forma a utilizar os benefícios de autoscaling (ou qualquer outra funcionalidade cloud-native), seus contêineres precisam ser imutáveis. Para isto, você precisa armazenar seus logs fora do contêiner, para que sejam persistente através de múltiplas execuções. O OpenShift permite você fazer deploy da stack EFK para agregar os logs dos hosts e das aplicações, não importando se os logs venham de múltiplos contêineres ou até mesmo de pods deletados.
A stack EFK é composta de:
- Elasticsearch (ES), um objeto para armazenar todos os
logs. - Fluentd, que coleta os
logse alimenta-os no Elasticsearch. - Kibana, uma console web para o Elasticsearch.
5 – Monitoring
Apesar de parecer que logging e monitoring solucionam o mesmo problema, eles são diferentes um do outro. Monitoring é a observação, e algumas vezes alerta, bem como o registro de informações. Logging é apenas o registro de informações
O Prometheus é um projeto open-source de monitoramento que pode ser usado para armazenar e consultar métricas, alertas e visualizações de sua aplicação. O Prometheus é talvez uma das escolhas mais populares de monitoramento de clusters Kubernetes. No blog do Red Hat Developers, existem diversos artigos cobrindo monitoramento usando o Prometheus. Você também pode achar artigos sobre o Prometheus no blog do OpenShift.
Você também pode ver o Prometheus em ação junto com o Istio em https://learn.openshift.com/servicemesh/3-monitoring-tracing.
6- Build and Deployment Pipelines
Pipelines de CI/CD (Continuous Integration/Continuous Delivery) não são estritamente um requisito obrigatório para suas aplicações. De qualquer maneira, CI/CD são frequentemente citados como pilares de sucesso do desenvolvimento de software e práticas DevOps. Nenhum software deveria ser implantado em produção sem um pipeline CI/CD. O livro Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation, do Jez Humble and David Farley, diz sobre CD: “Continuous Delivery é a habilidade de pegar as mudanças de todos os tipos, incluindo novas funcionalidades, mudanças de configuração, bug fixes, e experimentos, e leva-las à produção, ou até a mão dos usuários, de forma segura, rápida e de sustentável”.
O OpenShift fornece pipelines CI/CD embutidos como uma “estratégia de build”. Veja este vídeo em inglês que eu graver há dois anos atrás, no qual um exemplo de pipeline CI/CD usando Jenkins faz o deploy de um novo microserviço.
7 – Resilience
Enquanto o Kubernetes fornece várias opções de resiliência para o cluster propriamente dito, ele também pode ajudar a sua aplicação a ser resiliente através de PersistentVolumes que suportam volumes replicados. Os ReplicationControllers/deployments do Kubernetes garantem que um número específico de replicas do pod estejam consitentemente executando no cluster, que automaticamente trata qualquer possível falha em um nó.
Junto com resiliência, a tolerância a falha funciona como um meio efetivo de endereçar os problemas de confiabilidade e disponibilidade da aplicação. Tolerância a falhas também pode ser fornecida para a aplicação executando no Kubernetes, pelo do Istio através das regras de retry, circuit breakers e pool ejection. Você quer ver por você mesmo? Experimente o tutorial de Circuit Breaker em https://learn.openshift.com/servicemesh/7-circuit-breaker.
8 – Authentication
A autenticação no Kubernetes também pode ser fornecida pelo Istio através do mutual TLS authentication, que visa aumentar a segurança dos microserviços e de sua comunicação sem que haja qualquer mudança no código. O Istio é responsável por:
- Fornecer uma identidade para serviço de forma que possa representar seu papel de forma inter-operável entre clusters e a núvem.
- Fazer a segurança à comunicação serviço-a-serviço.
- Fornecer um gerencimento de chaves (keystore) para automatizar a geração de certificados digitais, distribuição, rotação e revogação.
Adicionalmente, vale a pena mencionar que você também pode executar o Keycloak dentro do cluster Kubernetes/OpenShift para fornecer autenticação e autorização. O Keycloack é o projeto upstream para o Red Hat Single Sign-on. Para mais informações, leia Single-Sign On Made Easy with Keycloak. Se você está usando o Spring Boot, assista ao vídeo do DevNation: Secure Spring Boot microserviços with Keycloak ou leia artigos do Keycloack.
9 – Tracing
Aplicações que usam o Istio podem ser configuradas para coletar trace spans usando o Zipkin ou o Jaeger. Independente da linguagem, framework, ou plataforma que você usa para construir a sua aplicação, o Istio pode habilitar o tracing distribuido. Veja em https://learn.openshift.com/servicemesh/3-monitoring-tracing. Também veja Getting Started with Istio and Jaeger on your laptop e o vídeo recente do DevNation: Advanced microserviços tracing with Jaeger.
Os servidores de aplicação estão mortos?
Vendo estas funcionalidades, você pode facilmente perceber como o Kubernetes + OpenShift + Istio podem realmente empoderar sua aplicação e fornecer funcionalidades que costumavam ser de responsabilidade do servidor de aplicações ou de um framework como o Netflix OSS. Isto significa que os servidores de aplicação estão mortos?
Neste novo mundo de aplicações conteinerizadas, os servidores de aplicação estão mudando para se tornar mais como frameworks. É natural que a evolução do desenvolvimento de software tenha causado também a evolução dos servidores de aplicação. Um grande exemplo desta evolução é a especificação Eclipse Microprofile que tem o Thorntail como servidor de aplicações, que fornece ao desenvolvedor funcionalidades como tolerância a falhas, configuração, tracing, REST (cliente e servidor), e assim por diante. De qualquer maneira, o Thorntail e a especificação Microprofile foram desenhados para serem bem leves. O Thorntail não possui a vasta gama de componentes requeridos por um servidor de aplicações Java completo. Ao invés disto, ele foca apenas em microserviços e no mínimo necessário de um servidor de aplicações para construir e executar suas aplicações como um aquivo .jar. Você pode ler mais sobre o Microprofile no blog do Red Hat Developers (em inglês).
Além do mais, aplicações Java podem ser funcionalidades como uma engine de Servlets, pool de conexões, injeção de dependências, transações, mensageria e assim por diante. Claro, frameworks podem fornecer estas funcionalidades, mas um servidor de aplicações também possui tudo que você precisa para construir, executar, implantar e gerenciar aplicações enterprise em qualquer ambiente indenpendente de estarem ou não dentro de um contêiner. De fato, servidores de aplicação podem ser executados em qualquer lugar, por exemplo, em bare metal, em plataformas de virtualização como o Red Hat Virtualization, em núvem privada como o Red Hat OpenStack Platform, e também em núvem pública como o Microsoft Azure ou Amazon Web Services.
Um bom servidor de aplicação garante a consistência entre as APIs que ele fornece e suas implementações. Desenvolvedores podem ter a certeza que fazendo o deploy de sua lógica de negócio, que requer certas funcionalidades, irá sempre funcionar por quê os desenvolvedores destes servidores (e seus padrões) garantem que estes componentes funcionam e evoluam juntos. Além do mais, um bom servidor de aplicação também é responsável por maximizar o throughput e a escalabilidade, uma vez que é responsável por gerenciar todas as requisições dos usuários. Ter uma latência reduzida e melhorando o tempo inicial de resposta, ajuda no provisionamento da aplicação. Ser leve, com um uso reduzido de memória minimiza o consumo de hardware. E finalmente, ser seguro o suficiente para evitar qualquer brecha de segurança. Para desenvolvedores Java, a Red Hat fornece o Red Hat JBoss Enterprise Application Platform, que preenche todos os requisitos de um servidor de aplicações moderno e modular.
Conclusão
As imagens do contêiner se tornaram o formato padrão para distribuir e empacotar aplicações cloud-native. Enquanto contêineres por si não fornecem nenhuma vantagem real para o negócio propriamente dito, o Kubernetes e seus projetos relacionados como o OpenShift e o Istio, fornecem os requisitos não funcionais que, até então, eram parte de um servidor de aplicações.
A maioria destes requisitos não funcionais que os desenvolvedores tinham o costume de usar em um servidor de aplicações ou de uma biblioteca como o Netflix OSS eram presas a um única linguagem como o Java. De outro lado, quando desenvolvedores escolhem usar estes requisitos não funcionais utilizando Kubernetes + OpenShift + Istio, eles não ficam presos a nenhuma linguagem específica, o que lhes permite usar a melhor tecnologia/linguagem para cada caso de uso.
Finalmente, servidores de aplicação ainda possuem seu lugar no desenvolvimento de software. De qualquer forma, estes tem se tornado mais como frameworks de uma linguagem específica, fornecendo um atalho para o desenvolvimento de aplicações uma vez que contém várias funcionalidades prontas e testadas.
Uma das melhores coisas a respeito da utilização de contêineres, Kubernetes e microserviços é que você não precisa escolher um único servidor de aplicações, framework, arquitetura, ou até mesmo linguagem para a sua aplicação. Você pode facilmente fazer o deploy de um contêiner com o o JBoss EAP executando sua aplicação Java EE junto com outros contêineres que utilizem novos microserviços usando Thorntail, ou o Eclipse Vert.x para programação reativa. Estes contêineres podem ser gerenciados pelo Kubernetes. Para ver este conceito em ação, dê uma olhada no Red Hat OpenShift Application Runtimes. Use o serviço de Launch para construir de fazer o deploy de uma aplicação de exemplo usando o Thorntail, Vert.x, Spring Boot, ou Node.js.
Você pode dizer que Kubernetes/OpenShift é o novo Linux ou até mesmo que o “Kubernetes é o novo servidor de aplicações”. Mas o fato é que um servidor de aplicações + OpenShift/Kubernetes + Istio se tornou o a plataforma “de facto” para aplicaçoes cloud-native!



Leave a comment